 Golang学习笔记
Golang学习笔记
# 学习笔记
# 常用命令说明
# go get
Go 源码的安装
# go mod
init:初始化,创建 go.mod 文件
download:下载模块到本地缓存
tidy:增加需要的依赖,删除不需要的依赖
实际开发中
尽量提交之前执行下
go tidy,减少构建时无效依赖包的拉取。
# 包、工作区、GOPATH
# 环境变量说明
GOROOT:Go 语言安装根目录的路径,也就是 GO 语言的安装路径。
GOPATH:若干工作区目录的路径。是我们自己定义的工作空间。
GOBIN:GO 程序生成的可执行文件(executable file)的路径。
GOPROXY: 是一个 Go Proxy 站点 URL 列表。
# 查看命令
$ go env | grep -E "GOPATH|GOROOT"
GOPATH="/Users/mym/go"
GOROOT="/opt/homebrew/Cellar/go/1.19.1/libexec"
2
3
4
# 依赖管理发展
Go语言依赖管理文章参考说明:一文搞懂Go语言的最新依赖管理 (opens new window)
# 程序实体的访问权限
三种
- 包级私有
- 模块级私有
- 公开的
使用说明
通过名称,Go 语言自然地把程序实体的访问权限划分为了包级私有(首字母小写)的和公开(首字母大写)的
在 Go 1.5 及后续版本中,我们可以通过创建internal代码包让一些程序实体仅仅能被当前模块中的其他代码引用。
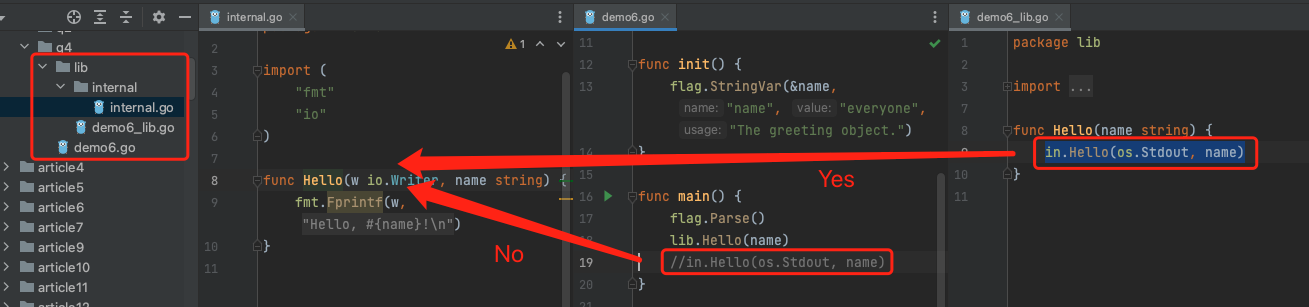
# 包冲突解决
给包名设置别名
import customerFlag "go_intro/flag"1默认导入整个包
import . "go_intro/flag"1如果非要用到包中的函数或者变量,可以隐式导入
import _ "go_intro/flag"1直接采用不同的包声明!
# 类型断言
# 类型断言表达式
- 语法形式是x.(T)。
- 其中的x代表要被判断类型的值。这个值当下的类型必须是接口类型的,不过具体是哪个接口类型其实是无所谓的。
- 这里的具体语法是interface{}(x),例如前面展示的interface{}(container)。

# 类型转换
# 注意点
整数类型值、整数常量之间的类型转换
int16转换为int8。请看下面这段代码:
var srcInt = int16(-255) dstInt := int8(srcInt)1
2整数在 Go 语言以及计算机中都是以补码的形式存储
int16类型的值-255的补码是1111111100000001
较高位置(或者说最左边位置)上的 8 位二进制数直接截掉,从而得到 00000001
又由于其最左边一位是0,表示它是个正整数,以及正整数的补码就等于其原码,所以dstInt的值就是 1
整数值转换为一个string类型的值
- 被转换的整数值需要是一个有效的Unicode代码点,否则转换的结果将会是"�"
- 字符'�'的 Unicode 代码点是U+FFFD
string类型与各种切片类型之间的互转的
- string类型向**[]byte类型**转换时代表着以 UTF-8 编码的字符串会被拆分成零散、独立的字节。
- string类型向**[]rune类型**转换时代表着字符串会被拆分成一个个 Unicode 字符。
# 别名类型
别名类型与其源类型的区别恐怕只是在名称上,它们是完全相同的。
两个别名类型。byte是uint8的别名类型,而rune是int32的别名类型。

# 数组和切片
# 区别
- **长度:**数组 长度是固定的,切片 是可变长的
- 类型:数组 是值类型,切片 是引用类型
- 切片可以看作是对数组的一层简单的封装,切片也可以被看作是对数组的某个连续片段的引用。
- 数组的容量
cap永远等于其长度len,都是不可变的。切片的容量却不是这样,并且它的变化是有规律可寻的
# 长度和容量分析
s3 := []int{1, 2, 3, 4, 5, 6, 7, 8}
s4 := s3[3:6]
fmt.Printf("The length of s4: %d\n", len(s4))
fmt.Printf("The capacity of s4: %d\n", cap(s4))
fmt.Printf("The value of s4: %d\n", s4)
2
3
4
5
- [3:6]要表达的就是透过新窗口能看到的s3中元素的索引范围是从3到5(注意,不包括6)
- s4的长度:6减去3
- s4的容量:其底层数组的长度8, 减去上述切片表达式中的那个起始索引3,即5
- 切片代表的窗口是无法向左扩展的
- 把切片的窗口向右扩展到最大的方法。对于s4来说,切片表达式
s4[0:cap(s4)]就可以做到
# ⭐️ Slice扩容规则
题外话:以前一直看到扩容规则后的老版本,直到有一天想拜读一下源码,才发现扩容规则已经改了
看源码和关注GitHub go版本更新才是最重要的呀
# 扩容步骤(1.17版本)
- 预估扩容后的容量 newCap
- 如果扩容前容量翻倍还是小于所需最小容量,那么预估容量就等于最小容量 oldCap * 2 < cap,newCap = cap
- 否则,判断元素个数
- 元素个数 oldLen < 1024 翻倍 newCap = oldCap * 2
- 元素个数 oldLen >= 1024 扩 1/4 newCap = oldCap * 1.25
- newCap 个元素占用多大内存
- 预估分配到内存 = 预估容量 * 元素类型大小
- 内存对齐:匹配合适的内存规格
- go语言内置的内存管理模块,提前向操作系统申请一批内存,分成常用规格管理起来,如8、16、32、48
- 扩容时,会帮我们自动匹配到足够大且最接近的内存
# 1.18版本后
预估 newCap 的规则改变了,主要有两个
- 1024 改为了 值为 256 的
threshold - 扩 1/4 改成了,扩
(newcap + 3*threshold) / 4
# 源码对比
// 1.17
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 1.18
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 改动的原因
旧版本的扩容规则,触发大于1024增长1.25倍的条件时,算出来的新容量要小于之前计算出的容量
新版本的扩容规则,随着切片容量的变大,增长比例逐渐向着1.25进行靠拢。
参考文章
https://blog.csdn.net/weixin_52690231/article/details/124827013
https://juejin.cn/post/7136774425415794719
# container包中的那些容器
# 为什么链表可以做到开箱即用?
延迟初始化,你可以理解为把初始化操作延后,仅在实际需要的时候才进行。延迟初始化的优点在于“延后”,它可以分散初始化操作带来的计算量和存储空间消耗。
每次操作先去判断链表是否已经被初始化,程序的性能将会降低
但一些方法是无需对是否初始化做判断
- Front方法和Back方法,一旦发现链表的长度为0, 直接返回nil就好了。
- 用于删除元素、移动元素,以及一些用于插入元素的方法中,只要判断一下传入的元素中指向所属链表的指针,是否与当前链表的指针相等就可以了
- 如果不相等,就一定说明传入的元素不是这个链表中的,后续的操作就不用做了。反之,就一定说明这个链表已经被初始化了
# Ring与List的区别
- 表示方式
- Ring:由它自身即可代表
- List:需要由它以及Element类型联合表示
- 表示维度
- Ring:只代表了其所属的循环链表中的一个元素
- List:代表了一个完整的链表
- 初始化指定元素数量(New函数在功能上的不同)
- Ring:可以指定它包含的元素的数量,一旦被创建,其长度是不可变的
- List:却不能这样做(也没有必要这样做)
- 初始化时的长度
- Ring:声明时,长度为1的循环链表
- List:声明时,一个长度为0的链表,List中的根元素不会持有实际元素值
- Len方法的时间复杂度
- Ring:O(N)
- List:O(1)
# 时间处理
// ConvTime 格式化微博时间
func ConvTime(timeStr, currentYear string) string {
nowTime := time.Now()
if strings.Contains(timeStr, "分钟前") {
min, _ := strconv.Atoi(ReParse(`^(\d+)分钟`, timeStr))
createdTime := nowTime.Add(-time.Duration(min) * time.Minute)
return createdTime.Format(TimeLayout)
}
if strings.Contains(timeStr, "小时前") {
hour, _ := strconv.Atoi(ReParse(`^(\d+)小时`, timeStr))
createdTime := nowTime.Add(-time.Duration(hour) * time.Hour)
return createdTime.Format(TimeLayout)
}
if strings.Contains(timeStr, "今天") {
return strings.Replace(timeStr, "今天", nowTime.Format("2006-01-02"), -1) + ":00"
}
if strings.Contains(timeStr, "昨天") {
createdTime := nowTime.Add(-24 * time.Hour)
return strings.Replace(timeStr, "昨天", createdTime.Format("2006-01-02"), -2) + ":00"
}
if strings.Contains(timeStr, "月") {
rp := strings.NewReplacer("月", "-", "日", "")
timeStr = currentYear + "-" + timeStr + ":00"
return rp.Replace(timeStr)
}
return timeStr
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27